Uncertainties in RB
During my BSc in Physics (Licenciatura en Física), I was always frustrated by the experimental courses—not because of the experiments themselves, but because of the analysis afterwards. Worst of all was dealing with statistics and numerical uncertainties! Ironically, those very tools later became central to my career.
Fast forward to the end of my PhD: I entered the quantum computing world through the technique now widely known as Randomised Benchmarking, or simply RB. Within the quantum computing community—hardware engineers and theorists alike—RB is regarded as the standard method for estimating gate fidelities. Of course, there are other approaches, but RB remains the primary tool for this purpose.
For those of us working more deeply in the QCVV sub-field, RB is better understood as a broad framework that has spawned numerous variants and related techniques. The boundaries between them are often blurry. For example, the traditional single-qubit and two-qubit Clifford RB can be seen as a special case of the Gate Set Shadow framework. Historically, RB also helped popularise the concept of unitary t-designs—ensembles of gates that mimic the uniform distribution over the unitary group up to the tth statistical moment. This unitary design concept is now essential for many randomised protocols to be practical.
Within the broader community, however, RB is often associated with some folk claims. Two common ones are:
- RB always produces an exponential decay from which fidelity can be extracted.
- The Clifford group is always a 2-design.
But both claims are conditional. The first depends on whether the average noise approximately satisfies certain assumptions. The second depends on the dimensionality of the group.
Reading between the lines of RB Data
Related to these, RB outputs can contain subtler information about the average noise within:
- The functional decay of the averages: If the average survival probabilities at chosen sequence lengths do not follow an exponential decay, one should proceed with caution. Questions arise: How many outliers are there? Are enough sequence lengths sampled? Should more circuits be run? Is there a quantitative measure of the deviations?
- The distribution of the survival probabilities: Even when averages fit an exponential decay, the distribution of individual survival probabilities at fixed sequence lengths can reveal the nature of the noise. Error bars (often the standard error of the mean) are useful, but they may conceal skewness or outliers.
The key point is that minimally processed data from RB —individual survival probabilities—can already indicate whether something could be more seriously wrong (non-exponential behavior, skewed distributions, big outliers). Moreover, the variance of these probabilities at each sequence length is related to the purity of the outputs, which in turn provides qualitative insight into the unitarity—a measure of how unitary the noise channel is.
This matters because it affects how much confidence one can place in the reported fidelity. One example is Interleaved Randomised Benchmarking, where the final average fidelity of a fixed gate is estimated using a couple of RB experiments. In this case, one can get nonsensical results such as fidelities going above 100% if this base confidence is low to begin with.
Importantly, I’m not referring to the uncertainty in the final fitted number (which depends on the fitting procedure and its assumptions). Rather, I mean the uncertainty inherent in each average point at every chosen sequence length. An intuitive way of thinking about this is that i) the spread of individual survival probabilities at fixed sequence length relates to the variance of the survival probabilities given your random Clifford sequence samples, which in turn ii) relates to how much the output states are getting probabilistically mixed, which then iii) roughly points to how non-unitary or dissipative the noise is.
Examples: URB and IIRB
Two protocols illustrate these ideas clearly: Unitarity RB (URB) and Iterative Interleaved RB (IIRB).
URB
URB estimates how unitary the noise is, with a fidelity-like measure, on average. It modifies standard Clifford RB by requiring measurements in all Pauli bases (effectively tomography for each circuit sample). Introduced in arXiv:1503.07865, URB also formalised the definition of unitarity. In our own work (arXiv:2409.02110), we extended URB and derived an upper bound for the unitarity of Pauli noise in terms of fidelity. Depolarizing noise achieves the lowest possible unitarity, while purely unitary channels have unitarity 1 - we bridged that gap so that you can tell whether the unitarity is close to that of purely stochastic noise (between upper-bound and depolarizing) or it certainly has a coherent contribution (between upper-bound and 1).
Running Clifford RB alongside URB highlights differences: two noise models with the same fidelity—one dominated by stochastic errors, the other by coherent errors—produce starkly different decays. The coherent case exhibits higher unitarity.
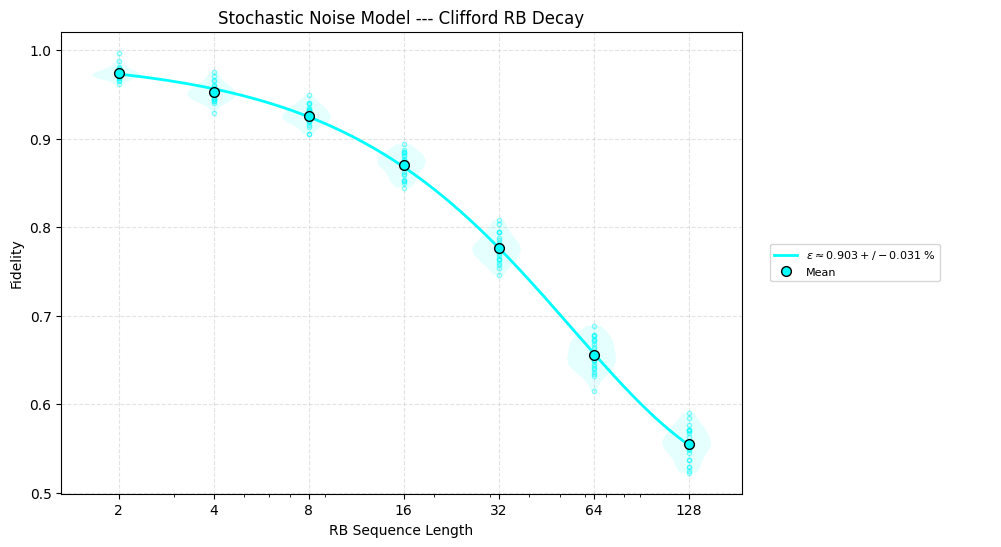
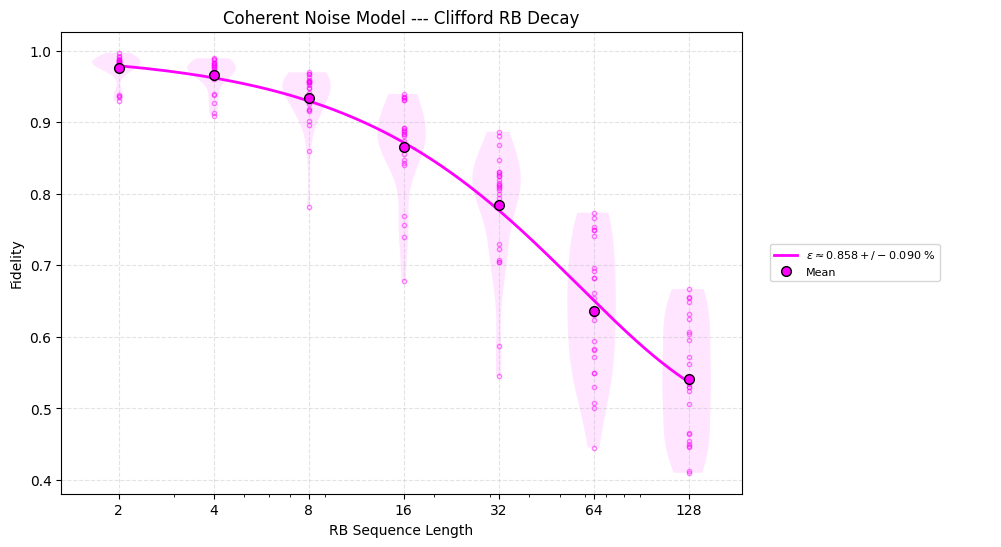
IIRB
IIRB tweaks Interleaved RB by interleaving the gate of interest multiple times and examining the estimated fidelities. First proposed in arXiv:1504.06597, it was later used in IQM’s demonstration of native two-qubit gates with fidelities above 99.9%.
The principle is simple: fidelity should decay linearly with the number of interleavings, equal to the slope of decay. If it decays faster, errors are accumulating more severely than expected under stochastic noise. Simulation with models as above for URB show a clear difference between stochastic and coherent noise.
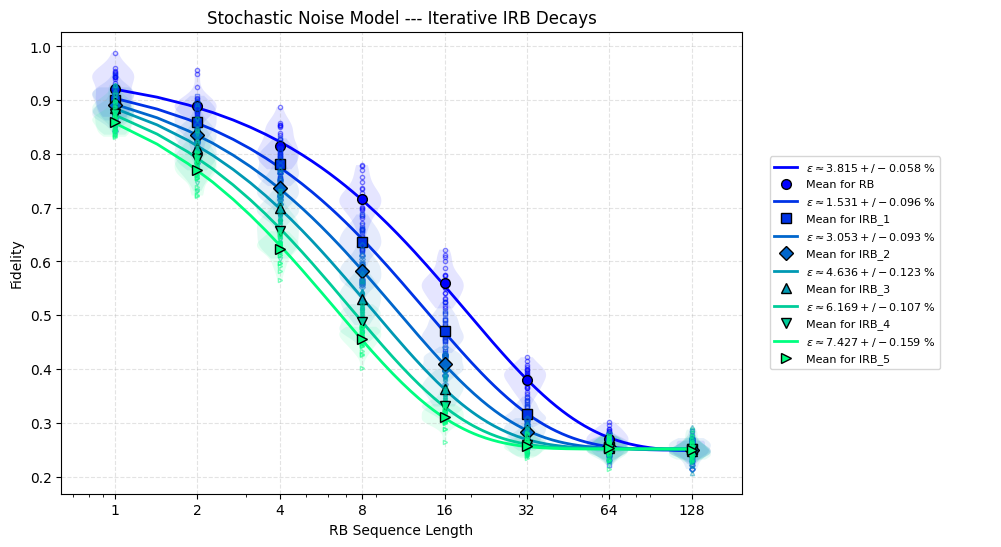
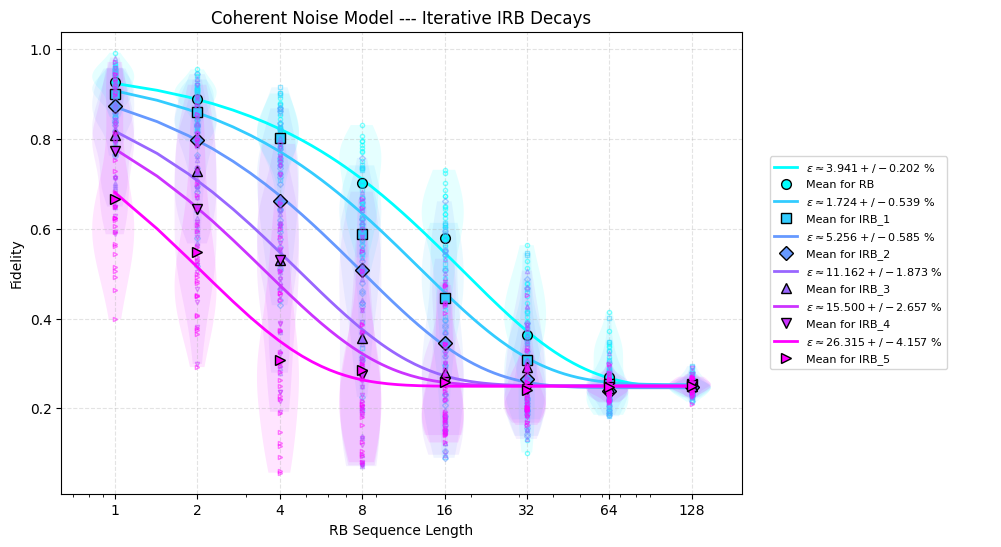
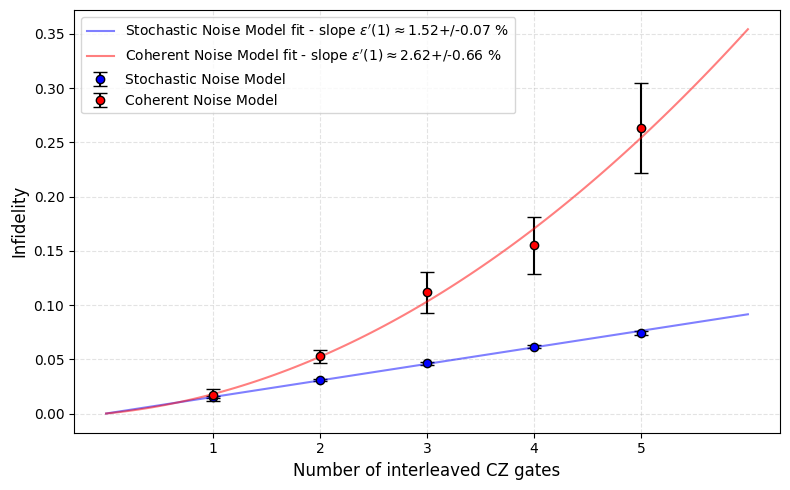
Why the coherence of noise matters
Ironically, when survival probability distributions are presented at several sequence lengths, they often resemble the coherent case. This is significant because coherence in noise impacts:
- Fault-tolerance thresholds
- Error accumulation over time
For deeper discussion on these, see arXiv:2207.08786 and this Qiskit seminar.
I often try to emphasise that fidelity in general is not a good quality metric, at least in this sense (it’s also mathematically dodgy 🫠 but that’s a story for another day), or just not a sufficient one. The main reason is that I often get the impression that fidelity has become one of those folk terms more broadly in the emerging quantum computing industry. To be fair, it is a really good figure of merit in the sense that it is the quality metric that we can estimate, at least approximately and with relative ease 😅